
Introduction
In this blog post we give an overview of the results of our recent paper [1].
We trained a Deep RL agent for our 1 v 1 real-time action strategy game, Heroic - Magic Duel, via ensemble self-play with only a simple reward of $\pm 1$. The agent obtains over 50% win rate against a top human player and over 60% against the existing AI.
For this purpose we created an environment that simulates a single battle in Heroic. It is a non-trivial reinforcement learning domain for multiple reasons: it is a real-time game with a large state space and a dynamic action distribution. Moreover, the information given to the players before a battle and at each its step is imperfect.
We first introduce the game itself and the Heroic reinforcement learning environment with its state and actions spaces. Then we discuss the architecture of the agent and the training curriculum. We also ran a series of experiments, which we present at the end.
Heroic RL Enviroment
Game overview
A battle takes place on a symmetrical map split into 3 lanes 1 v 1. The lanes are separate parallel battlefields which all start at one castle and end at the other. The goal is to destroy the enemy castle. Before the battle, each player selects a deck of 12 cards to be used out of total 56 cards in the game. During the battle, players cast their cards (placed at the bottom of the screen) at a desired location on the map, effectively spawning the units there (the yellow arrow in the figure below). A unit can be cast only between one's own castle and the closest enemy unit, but no further than the furthest friendly unit and the half-length of the lane. Once cast, a unit on the battlefield automatically starts moving towards the opponent's castle until it reaches it (then it starts lowering the opponent's castle health points) or encounters an enemy unit (then it starts lowering the enemy unit's health points). As soon as any player's castle health points reach $0$, the battle is over and their opponent wins.
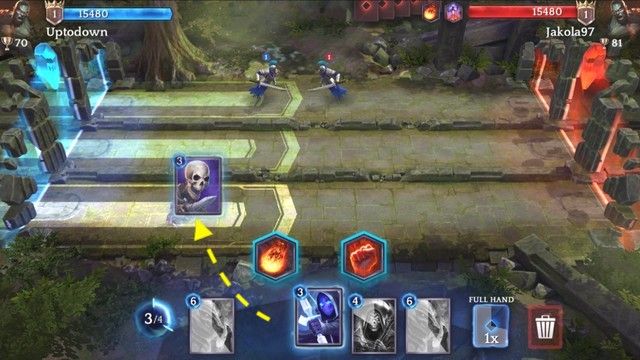
There is a number of properties that determine unit abilities, e.g. range, attack type. This means that that certain unit types are good against some unit types and weak against other types. This gives the single unit selection the flavor of an extended rock-paper-scissors problem.

Card casting is limited by mana, moreover players can have up to 5 cards in hand. The deck holds an infinite supply of cards in the ratio determined by the 12 cards selected before the battle.
In addition players select 2 (out of a total of 25) spells before the battle. Spells are special actions which, once played, cannot be used for a fixed period of time. Depending on the spell they can be played (and take effect) at a particular location on the map, one lane or the whole map.
In order to understand the game mechanics better, see an example Heroic battle below.

RL Environment
Generally, in a reinforcement learning environment at any given point in time $\textbf{t}$ and given a state, agent takes an action, for which it gets a reward. In this framework, the goal of the agent is to maximize its sum of rewards over time. Here is the classical diagram of the feedback loop in reinforcement learning [2].
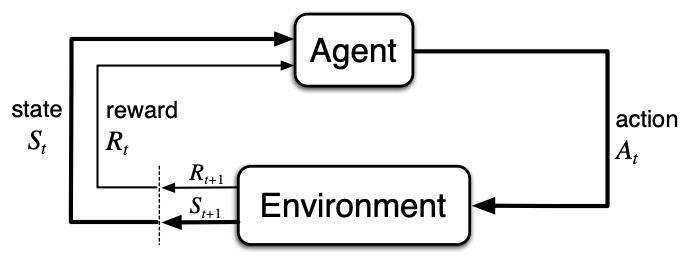
Hence, to make our problem precise, we shall specify the Heroic RL environment by defining its states, actions and rewards. Formally states should contain complete information about the environment, which is almost never the case in real applications. Thus we replace state with observation, which contains "a subset" of complete information about the world.
Observations, actions and rewards
We represent an observation as $(o_{\textrm{spatial}}, o_{\textrm{non-spatial}})$, where we refer to $o_{\textrm{spatial}}$ as the spatial component and to $o_{\textrm{non-spatial}}$ as the non-spatial component of the observation.

The spatial component is a tensor of shape $D \times L \times 2U$, where
- $U$ is the total number of units in the game (we use $U=56$)
- $L$ is the number of lanes ($L=3$)
- $D$ is the number of discretization bins per lane (we use $D=10$)
We set the value of $o_{\textrm{spatial}}(d, l, u)$ to be the sum of health points (in percent) of own units of type $u$ at coordinates $(d,l)$ for $u < U$ and the sum of health points of opponent's units of type $u - U$ at the same coordinates for $u \geq U$.
$o_{\textrm{non-spatial}}$ is a vector of length $A+3$ (where $A$ is the total number of actions, including both cards and spells) that contains the waiting times/availability of each action, castle health of both player and battle time.
Actions are represented as triples $(a, x, y)$, where $a$ is the selected action type and $(x, y)$ are the desired coordinates for the action. The set of action types consists of card action types, spell action types and the no-op action. Note that depending on the state of the game, certain action types and coordinates may not be available.
We use a simple reward of $\pm 1$ depending on the outcome of a single battle.
Policy
We model our agent's policy as mapping $\pi_{\theta}\colon \mathcal{A} \times \mathcal{O} \to [0, 1]$, where $\mathcal{A}$ is the set of action types, $\mathcal{O}$ is the set of observations and the value $\pi_{\theta}(a, o)$ is the conditional probability of taking action $a$, given observation $o$. Parameter $\theta$ denotes the weights of a neural network, whose architecture we specify in the following.
Policy architecture
Similarly to the Atari-net architecture in [3] we preprocess the spatial observation with a convolutional neural network, the non-spatial observation with a fully connected neural network. Both outputs get concatenated after appropriate flattening.
We found it useful to make some modifications to the head of the Atari-net baseline, which simply outputs distributions $a$, $x$, $y$ independently. In particular we condition coordinates on actions types and output a single distribution of coordinates, instead of sampling $x$, $y$ independently. The conditioning is done by simultaneously outputting an action type distribution and distributions of coordinates for every possible action type. Then an action type gets sampled and only the spatial distribution corresponding to the selected action type is used to sample $z = (x, y)$, with all the other distribution being masked out. Moreover, we use two policy heads, one for card actions and another for spell actions.
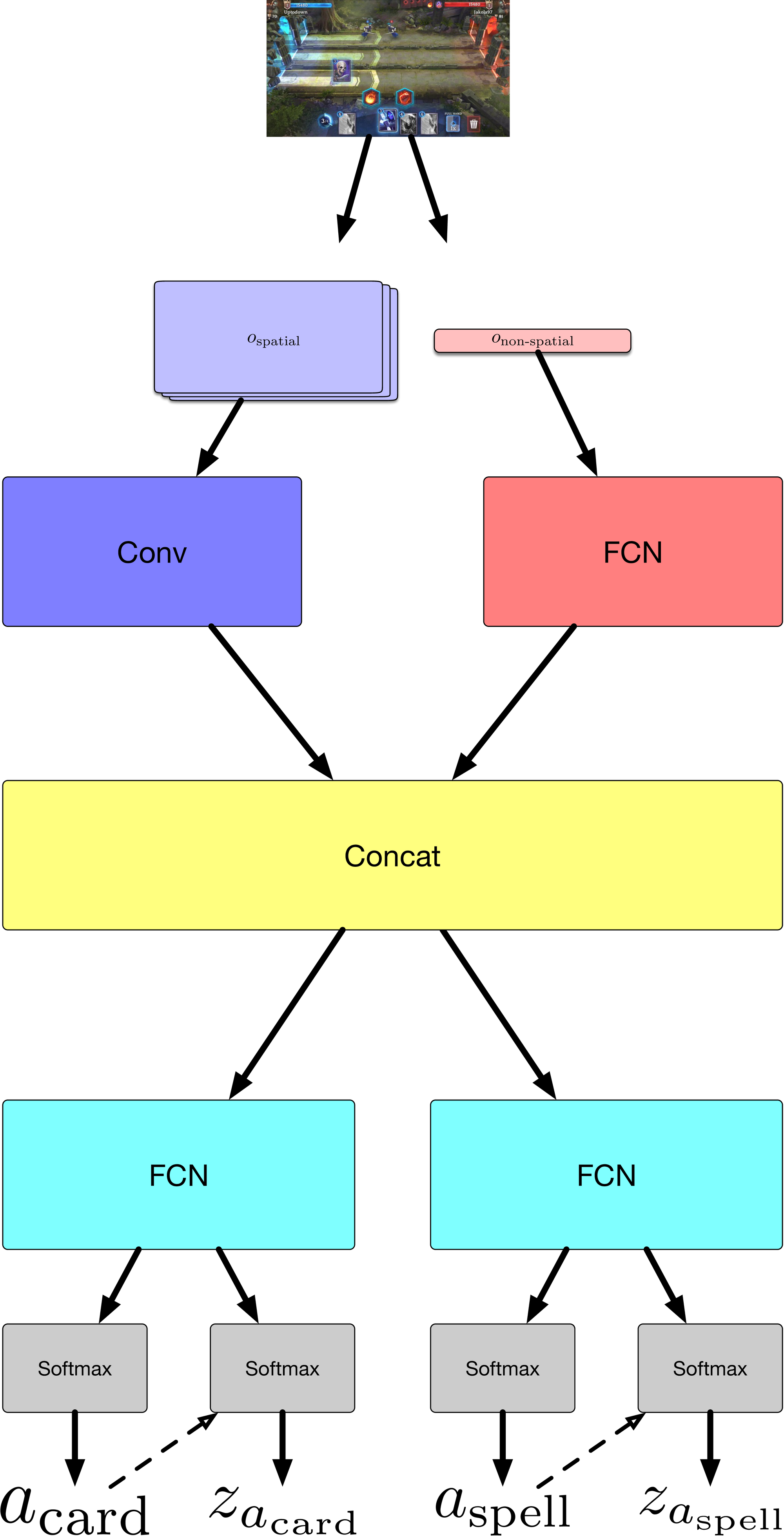
Note that that the above procedure has to be combined with appropriate masking of available action types and available coordinates in the softmax layer (depending on the rules of the game), similarly to [3].
In addition to the policy network, we use a value network which outputs a predicted value directly after the concatenation of the output of the convolutional and the fully connected network.
The policy network is updated using proximal policy optimization (PPO) [4] and the value network is updated using the square loss between the discounted observed reward and the predicted value, similarly as in the PPO paper. For more details on the architecture and the hyperparameters see our paper.
Training Curriculum
We trained agents by competing against different types of opponents in iterations consisting of multiple (typically $> 1000$) battles. Before every battle both players, the agent and the opponent, obtain a deck sampled from a preselected set of over 200 decks that we chose in collaboration with the game designers, in order to make the used decks sensible. We used two different training curricula when training agents.
- Training via Competing against AI. There are two existing Heroic AIs, the first one is a rule-based system and another one is a tree-search AI. We simply train agents against a fixed AI, which gives the advantage of quicker progress and allows faster hyperparameter selection, but of course such training may result in low versatility.
- Training via Self-Play with Ensemble of Policies. Another approach that we have taken is ensemble self-play [5]. During the standard self-play training the agent is competing against the latest previously trained policy. Ensemble self-play is similar, but there are multiple policies trained in parallel and the opponent is sampled from these policies. Additionally, we use a parameter that controls the number of previous versions of the policy that we take into account when sampling the opponent [5]. In our experiments we used an ensemble of three policies.
Experiments
In this subsection we report the results of our experiments. We carried out the experiments with two variants of the game: without spells and with spells. We found the latter version considerably more complex, for which we give arguments in the third experiment, while in the first two experiments we consider the game without spells.
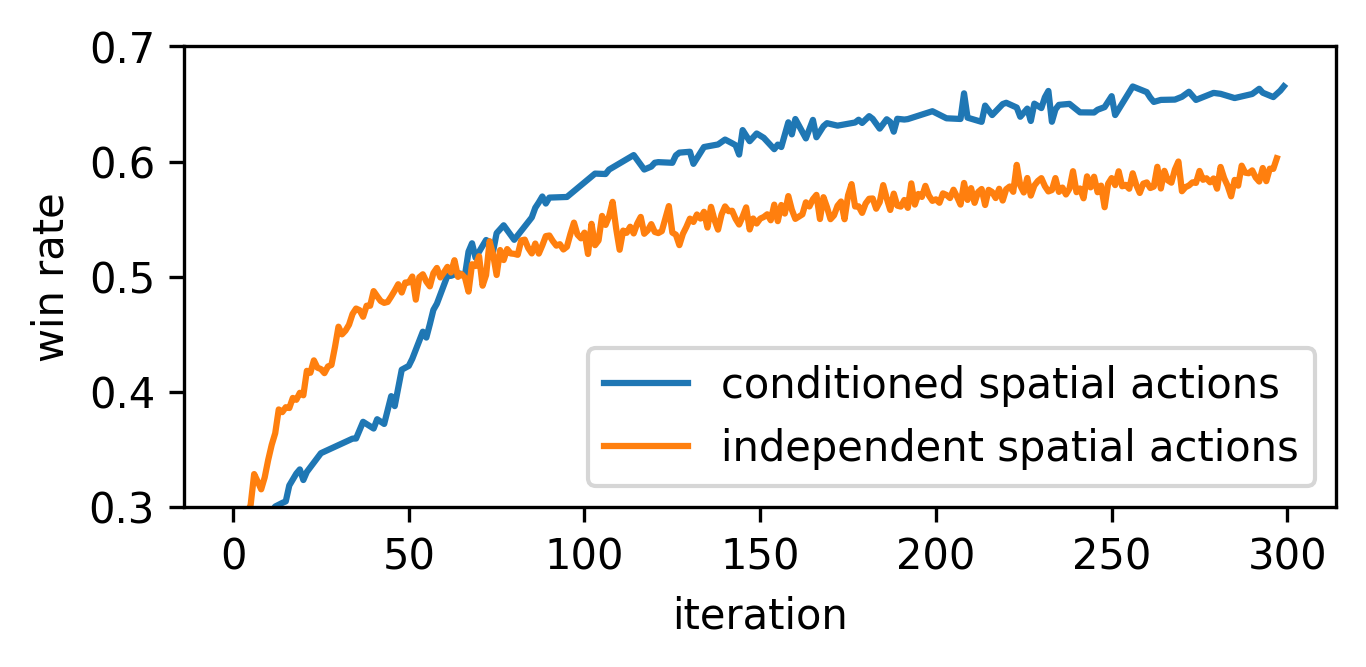
Sampling spatial actions
We benchmarked our policy architecture, which conditions spatial actions on the selected action type, against the simple architecture that simply samples action type and coordinates of the action independently. We noticed a clear improvement of performance already after several hundred iterations when training against the rule-based AI. Note, however, that in the early phase of training the simpler policy is dominant. We think that this is because the simpler agent discovers basic rules of casting cards more quickly and the more complex agent needs more training time for that.
Self-Play
We trained agents via ensemble of $n=3$ policies as introduced in the previous subsection. We report the following performance of our best self-play agent:
- 64.5% win rate against the rule-based AI
- 37.3% win rate against the tree-search AI
- We also tested the agent against a human player, a developer that worked on the game, which is within top 95th percentile of Heroic players. In total of 20 battles played with random decks (from the preselected pool) the self-play agent obtained 50% win rate against the human player.
In order to compare all the mentioned AIs against the human player we additionally tested all the agents in a series of 10 battles. We obtained the following performance of the agents.
- Self-play agent: 60% win rate against the human player
- Rule-based AI: 20% win rate against the human player
- Tree-search AI: 50% win rate against the human player
What we found interesting is the intransitivity of the results. Namely, the self-play agent performs worse against the tree-search agent in a direct comparison, however the self-play agent performs similarly, or even better, against the top human player.
Enabling Spells
We observed that enabling spells makes learning considerably harder. Training with enabled spells against the rule-based AI gave us promising results, but there is a clear drop in performance compared to the same agent trained in the no-spell version of the game. We empirically discovered that in some cases the agent struggles to play no-op actions optimally in combination with spells, and sometimes wasting a spell may mean losing the battle. We later found that scaling up the training helps to considerably mitigate this issue, see the following subsection.
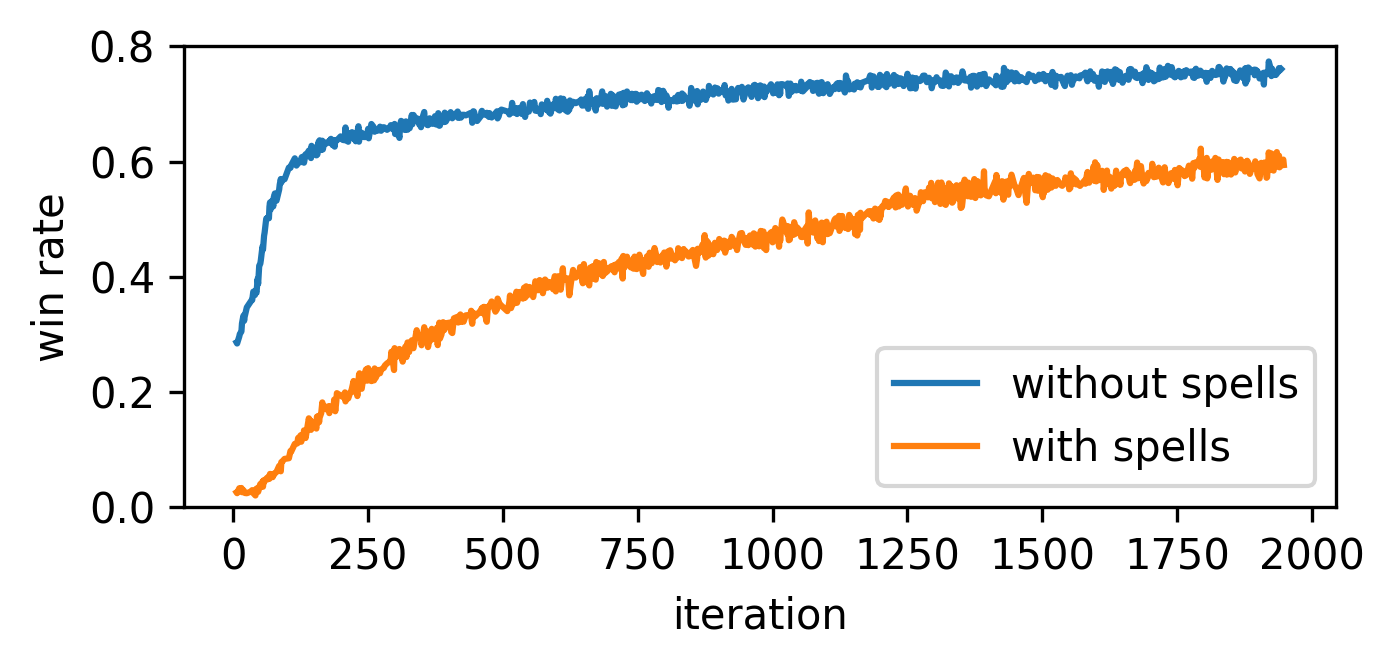
Scaling up
Since the release of the paper we scaled up experiments in order to close the performance gap between no-spell and spell agents and, moreover, to train an agent with the extended pool of decks that includes all cards and spells that are available in the game. Increasing the number of battles per iteration (approximately 7 times) and the training time, without any major architecture changes, we obtained the following results with the extended pool of decks.
- 76% win rate against the rule-based AI
- 39% win rate against the tree-search AI
Deep RL Agent in Action
Finally, here is a snapshot of the self-play agent (on the left) playing against the tree search AI and performing a successful counterattack.

References
[1] Warchalski, Michal, Dimitrije Radojevic, and Milos Milosevic. "Deep RL Agent for a Real-Time Action Strategy Game." arXiv preprint arXiv:2002.06290 (2020).
[2] Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction. MIT press, 2018.
[3] Vinyals, Oriol, et al. "Starcraft ii: A new challenge for reinforcement learning." arXiv preprint arXiv:1708.04782 (2017).
[4] Schulman, John, et al. "Proximal policy optimization algorithms." arXiv preprint arXiv:1707.06347 (2017).
[5] Bansal, Trapit, et al. "Emergent complexity via multi-agent competition." arXiv preprint arXiv:1710.03748 (2017).
[6] Vinyals, Oriol, et al. "Grandmaster level in StarCraft II using multi-agent reinforcement learning." Nature 575.7782 (2019): 350-354.
[7] OpenAI, C. Berner, et al. "Dota 2 with large scale deep reinforcement learning." arXiv preprint arXiv:1912.06680 (2019).