
Introduction
In this blog post we give an overview of some of the recent advancements in deep learning-based character animation. In particular, we discuss [1], [2] that provide a way to use neural networks to turn motion capture data into interactive character controllers.
In the following we overview [2], which builds upon [1], and point out the differences along the way. At the end we also discuss some initial results that we obtained using the model from [2].
Data
[2] deals with quadruped agents, which are known to be challenging for animation processing. 30 minutes of dog motion capture data is used in the paper and the preprocessing includes classifiying the animations into different motion modes such as locomotion, sitting etc. This is contrast to [1], which deals with biped agents and requires additional preprocessing for the locomotion phase. The latter is one of the main differences between the models used in these papers and we explain it in more detail below.
Mode-Adaptive Neural Networks
The model introduced in [2] is the so-called mode-adaptive neural network (MANN).
The network takes in the following information:
- Trajectory data: root positions (projected on the $2d$ plane), directions and velocities in $t-1$ previous frames, in the current frame and in the next $t$ frames, i.r. $2t$ frames in total.
- Joint data: positions of joints, their rotations and velocities in the previous frame.
- Target velocities: desired velocities in the future $t$ frames.
- Action variables (e.g. locomotion, sitting, jumping).
The output consists of:
- Trajectory data: corresponding to the trajectory input data shifted by $1$.
- Joint data: corresponding to the joint input data shifted by $1$.
- Root motion: by how much the root changed its position and rotation.
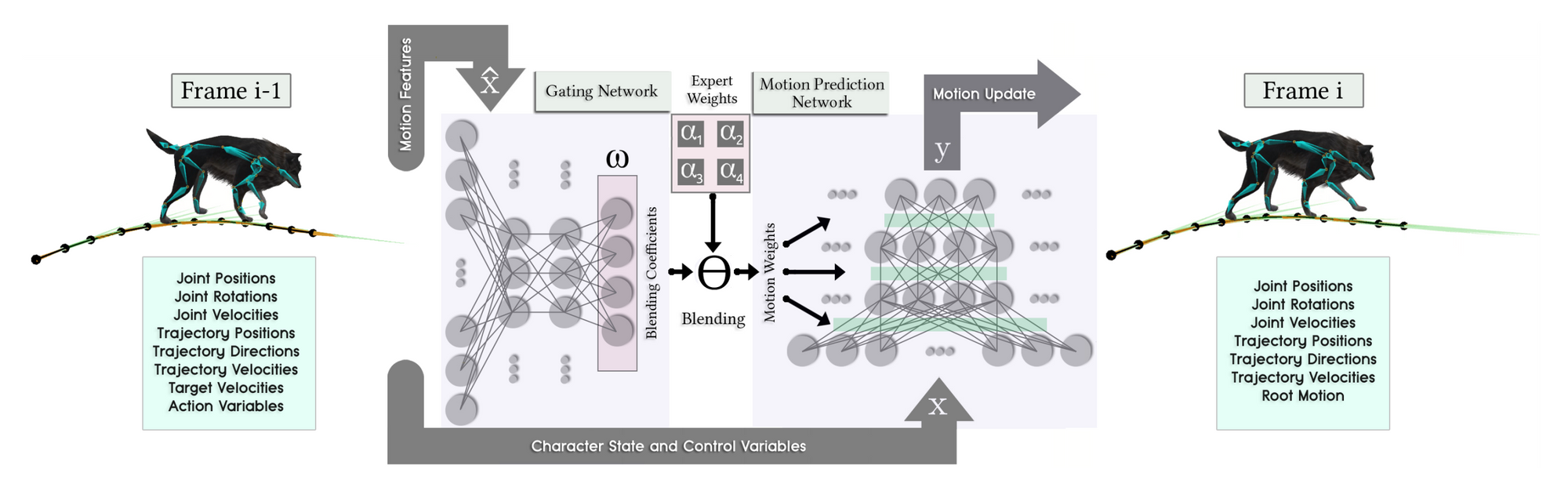
Importantly, there is a difference between constructing the input at training and test time. At training time we can simply extract the trajectory and joint data, while target velocities and action variables must be constructed as if there was a user input controlling the character. On the other hand, at test time target velocities and action variables are computed directly from user input, joint data can be computed from the previous frame and the trajectory data must corrected using user input. The paper employs $t=6$ and utilizes every 10th frame.
Note that the model takes in sequential data, but it is not an RNN model. In fact, the authors compare their approach to existing RNN architectures and claim better performance.
Although no explicit recurrent model is used, the network still infers the motion state. The key idea is that the whole model consists of two three-layer feedforward neural networks, the gating network and the motion prediction network. They interact in the following way: the first one is used to obtain the implicit phase of locomotion, which is represented by a $k$-dimensional vector. Next, the output coefficients are used to blend the weights of $k$ different neural networks as a linear combination. For instance, in the diagram above, $k=4$.
The model improves upon [1], in the sense that [1] requires annotating phase of gait (which also needs to be predicted for bootstrap), which is part of the input and the output of network. The linear combination of $k$ neural network weights is then obtained by using a spline function that produces neural network weights for a given phase, see [1] for details. [2] does not require this, since the phase predicted implicitly by the gating network and fed into to the motion prediction network. Note that phase annotation is even more tedious for quadruped agents, which are tackled by this paper.
Examples
To see how the models work in practice, check out the videos provided by the authors of [1] and [2]:
Exploring MANN
We decided to explore the model a little bit more and obtained promising initial results given the amount of data used. Here we give a brief summary of our findings concerning customization of the open-sourced code for [2], which can be found in [3].
MANN requires mocap animations, for which [3] provides a preprocessing pipeline. We used several minutes of in-house football animations. Similarly as in [2] each recording contains information on the positions of joints of a person in the footage and is recorded with 60 fps. Moreover, each recording potrays a particular motion mode (idle, run, sidestep) or, sometimes, a transition between two behaviors. We preprocessed and labeled the animations and the transitions using the toolbox provided by in the repository [3].
As soon as we did the preprocessing, adapting the neural network model provided in the repo and training was rather straightforward. Testing the model involved more work, since the paper deals with quadruped agents the original implementation provides testing functions in Unity for such characters. We needed to adjust the scripts for our underlying football character, which required a number of sensitive modifications to the existing code and to the parameters in order to improve responsiveness.
References
[1] Holden, Daniel, Taku Komura, and Jun Saito. Phase-Functioned Neural Networks for Character Control
[2] Zhang, He, Sebastian Starke, Taku Komura, and Jun Saito. Mode-Adaptive Neural Networks for Quadruped Motion Control
[3] AI4Animation repository